失敗データを機械学習に取り入れる
Incorporation of Failure Data into Machine Learning
機能材料や化学反応を効率的に探索するマテリアルズ・インフォマティクスが注目されている。多量の学習データには材料・論文データベース,量子化学計算値あるいはハイスループット実験の結果が用いられる。しかし,論文は多くの場合,目的とする特性が高い系や条件に偏っている。一方で,多くの実験化学者は(筆者も含め)日々失敗に直面しているが,これらは実験ノートや記憶に刻まれるだけで日の目を見ることは通常はない。したがって,上記のデータベースは成功データに偏っているという問題を本質的に有する1, 2)。
Strieth-KalthoffらはBuchwald-Hartwig反応とSuzukiカップリングに注目し,実験ノイズ,選択バイアス,報告バイアスの検討を行った3)。反応収率を予測する機械学習モデルを検討したところ,学習データに失敗データ(negative data)を加えることで予測精度が向上することを示した。
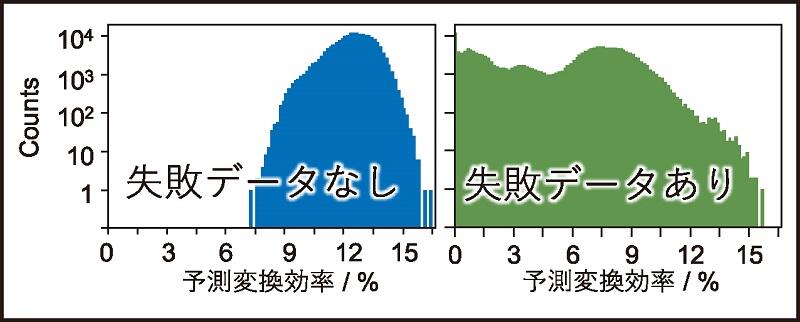
筆者らは有機薄膜太陽電池ポリマーを仮想合成し,機械学習によるハイスループットスクリーニングを報告している。この中で,通常は論文には報告されない失敗データ(低溶解度や低分子量により薄膜化が不可能と考えらえるポリマー)を人工的に生成して学習データの一部として取りいれたところ,実験の変換効率(PCE)の予測精度を向上させることに成功した4)。仮想合成ポリマー(20万種類)に対しても,失敗データを加えることで予測PCEの分布は広くなり,よりもっともらしい(一般に実験上よく経験するような)予測結果が得られている(図)。ほかの機能材料においても,失敗データの活用が期待される(しかし,失敗を望んでいるわけではない)。
1) P. Raccuglia et al., Nature 2016, 533, 73.
2) W. Berker et al., J. Am. Chem. Soc. 2022, 144, 4819.
3) F. Strieth-Kalthoff et al., Angew. Chem., Int. Ed. 2022, 61, e202204647.
4) Y. Miyake et al., Chem. Mater. 2022, 34, 6912.
佐伯昭紀 大阪大学大学院工学研究科